Abstract
Purpose: The aim of this study was to investigate the prevalence of clustering by health professionals in individually randomised controlled trials (iRCT), and its adjustment in both the sample size calculation estimates and the analysis of the data collected in iRCT (that is, trials that randomise individuals only). As a result, cluster randomised controlled trials will not be the part of this review study. Additionally, the authors aimed to discover the prevalence of the various forms of clustering in iRCT.
Methods: iRCT, in which the intervention was delivered by a health professional, were electronically searched in three medical journals. The dates searched were from 1st January 2000–31st August 2009. The retrieved trials were then screened to exclude those with complex designs and trials with more than two parallel arms. The selected trials were then fully reviewed for the presence of clustering effects and any corresponding adjustment. Data about the sample size calculation in the selected trials were also included. A basic form was generated for the purpose of data extraction from each of the selected trials.
Results: Of the 130 iRCT reviewed, clustering of outcomes was present in 127 (98%) trials. Only 61 trials (47%) had adjusted for the clustering effects in their design and analysis, while 53% of the trials had ignored the clustering effect, and hence no adjustment had been made in the trial design or analysis.
Regarding the various forms of clustering, clustering by centre in multicentre trials was found in 79 trials (60%), followed by natural clustering in 26 trials (20%), and clustering imposed by the design of the study in 23 trials (18%).
Conclusion: Potential clustering of outcomes exists in almost all iRCT; however, this review found that <50% of iRCT took clustering into account and adjusted the sample size calculation and statistical analysis of this data for clustering. Almost half of the reviewed iRCT ignored the clustering effect. As a result, inaccurate and nongeneralisable results could have been generated.
BACKGROUND
Researchers that individually randomised controlled trials (iRCT) assume that the observed outcomes of participants are independent. In practice, there are a number of situations in which there is some doubt about the validity of this assumption. One example is the correlation, or clustering, of the observed outcomes in participants treated by the same health professional.1 The importance of this issue was emphasised by Lee and Thompson,1 who assessed clustering in 42 iRCT and concluded that clustering of outcomes exists in almost all iRCT, but is usually ignored in the analysis, which leads to underestimates of uncertainty and overly extreme p values.1 In another article, Lee and Thompson proposed random effect models to allow for such clustering and investigated their effect on estimation and interpretation of the treatment effect.2
INTRODUCTION
What Does the Term Clustering Mean?
The term clustering usually diverts the mind of the reader towards the cluster randomised controlled trials, wherein the groups, or clusters, of patients (rather than individuals) are randomised to a treatment either because of the nature of the treatment or to prevent contamination between treatment groups.3 However, in this review, clustering in iRCT will be analysed.
In iRCT, clustering means that the observation(s) about patients and observed outcomes in iRCT may be correlated due to differences in the behaviours of the health professionals actively delivering the intervention, sociodemographic differences between the patients, or the design of the study.1 Observed outcomes clustering can also occur by single centres when participating in larger multicentre randomised controlled trials.2
Why is it Important to Consider the Clustering Effect?
Clustering of outcomes in randomised trials reduces the effective sample size, reducing the power of a trial to detect an intervention effect.4-6
Additionally, clustering also affects the generalisability of the results and conclusions.1 The results obtained and conclusions drawn from a trial cannot be generalised to the whole population if the potential of clustering for outcomes exists in a trial. For example, in therapy trials the sample of therapists in the trial should be representative of those who are going to deliver the intervention in practice,7 otherwise, the results obtained cannot be generalised.
In What Forms Does Clustering Exist in Individually Randomised Controlled Trials?
Clustering may be imposed by the design of the trial; this inherent clustering as a result of trial design has been noted in a trial comparing a new one-stop clinic with a dedicated breast clinic for breast cancer screening.8 In another form, clustering can be natural rather than imposed either because of the sociodemographic differences between patients or because of the general practitioner’s or the practice’s influence on delivering the intervention, as observed in a trial comparing fusidic acid cream with placebo for the treatment of impetigo.9
Clustering can also appear by centre in a multicentre trial, which was seen in a study comparing the cytological surveillance with immediate referral for colposcopy in management of women with low-grade cervical abnormalities.10 Observations from the same centre were similar and therefore more correlated and clustered than those from different centres: this phenomenon defines the centre effect.11
How Can Clustering Effects Be Adjusted?
In iRCT the clustering effects can be accounted for by anticipating them at the time of trial design and increasing the sample size accordingly.12
Adjustment for the clustering effects in iRCT can also be conducted during the statistical analysis of a trial by using various statistical models.4 When analysing data from a multicentre trial, the estimation of the main treatment effect must take into account the differences seen between each centre.13-15 This statistical method to limit the effect of clustering is widely accepted, but there is no real consensus on the statistical model to use.16-20 However, the selected method depends on the application of the trial’s conclusion.11 If conclusions apply across the participating centres or if the centres cannot be considered as a random sample from a population, the analysis of data will involve a fixed effects regression model. On the contrary, if one wants to extend the results to all the centres that could be concerned by the experimental treatment, the analysis of data will involve a mixed effects model.11
Time Trend of Clustering in Individually Randomised Controlled Trials
At present, there is no obvious trend of clustering prevalence and its accommodation in iRCT. One of the objectives of this review is to identify the time trend of clustering prevalence in iRCT and the according adjustments in such trials. The aim of this study is to conduct a systematic analysis of the iRCT for the potential effects of clustering by health professionals.
Objectives of this study
- To identify the prevalence of clustering in iRCT.
- To identify whether the researchers have allowed for clustering effects or ignored clustering effects in the selected iRCT.
- To explore the different ways used to accommodate for clustering effects in the selected iRCT.
- Analyse the time trend analysis of the presence of clustering in iRCT and any according adjustment.
METHODOLOGY
Trials to be Included in This Study
Only iRCT conducted by healthcare professionals have been included in this study. The term healthcare professional encompasses doctors, nurses, physiotherapists, and acupuncturists. iRCT involving a pharmaceutical and/or health technology have not been included in the final selection of the studies that were reviewed. Likewise, cluster randomised controlled trials were excluded during the final selection of the articles.
Study Design
This study is a systematic review of iRCT published in three selected journals from 1st January 2000–31st August 2009. The journals were selected for this study due to their diverse impact factors (at the time of the study) and the ease of access to the fully published articles from the university portal of the University of Sheffield. The retrieved articles were fully reviewed for the presence of various forms of clustering, relevance of the assumptions made while calculating sample size, and adjustment made for the effect of clustering during statistical analyses.
Strategic Plan for the Search
Basic literature search
The electronic databases searched for relevant literature were Medline® via OVIDSP online, the university portal/OVID online, and Google scholar. The database was searched from 1950 to date. The keywords used for electronic searching were “clustering”, “clustering effects”, “statistical models”, “randomised controlled trials”, “randomized controlled trials”, “natural clustering”, “multicentre trial”, “adjustment for clustering”, “health professional”, “individual randomized trials”, “individual randomized trials”, “sample size”, “sample size calculation”, and “random effect model”.
The keyword “clustering” yielded 27,084 papers, while the terms “randomized controlled trials” and “randomized controlled trials” yielded 286,121 and 6,006 papers, respectively. The search was narrowed on the basis the of forms of clustering, models to allow for clustering, adjustment methods, sample size, and sample size calculation. The search was further narrowed by only selecting iRCT and excluding cluster randomised trials. Finally, iRCT conducted by pharmacists and those with technological subjects, such as Helicobacter pylori, cardiac markers, and other tests were also excluded as these studies did not meet the inclusion criteria.
Individual journal search
A separate search strategy was used for accessing and scrutinising each of the three journals. The portal and search strategy used for each of the journals is briefly discussed below.
BMJ
The yearly archives of the online issue of BMJ were accessed via the HighWire Press Free line using the university library electronic journal database. Within each year, the full reports of the articles regarding the primary care/general practice were accessed, and the retrieved articles were categorically arranged on the basis of their study design. The articles in the education and debate portion of the archives were not accessed.
The Lancet
The electronic search was made using ScienceDirect via the university library electronic journals database. The terms “randomized controlled trials” and “randomised controlled trials” were searched via ScienceDirect.
Articles were then selected or excluded by applying the limitations of the iRCT in the specified time period (1st January 2000–31st August 2009), which reduced the number of the articles to 82.
Journal of Psychiatry and Neurosciences
PubMed Central, accessed via the electronic journal database of the university library portal, was used to search for JPN articles. The volumes of the JPN were scrutinised in detail from January 2000–July 2009. This search yielded 30 randomised controlled trials.
Screening of the titles and abstracts of the retrieved articles
The full literature search yielded 381 relevant articles. Two independent researchers screened the titles and abstracts of the retrieved articles, and, as a result, 160 articles were excluded.
Full text review of the retrieved articles
A review of the full text of the selected articles was conducted, and, as a result, 91 articles were excluded on the basis of full text review because they did not meet the inclusion criteria. Among these, trials with the factorial, crossover, and/or cluster design were excluded. Additionally, the follow-up studies were excluded from the retrieved articles (Figure 1).
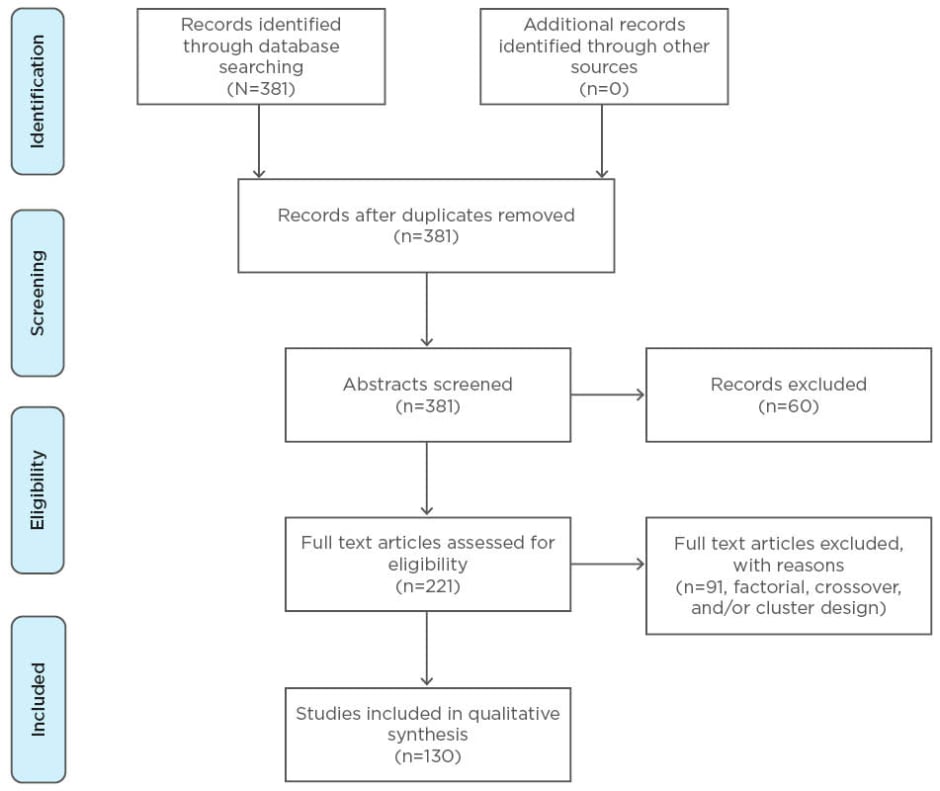
Figure 1: The identification, screening, and selection of the studies detailing individually randomised controlled trials included in this investigation.
Data Extraction
The iRCT selected for the final analysis were thoroughly reviewed for data extraction. A form was generated and used for the data extraction during the analysis of the selected iRCT. Data was extracted both from full text published iRCT and online extra material and registration websites.
Data extraction from the full text of the articles
The full text articles were studied and data regarding the general characteristics of the iRCT, sample size calculation, and statistical adjustments made for clustering were recorded.
General characteristics of the selected studies
The journal of publication, the year of publication, the type of intervention, number of multicentre trials, the health professionals conducting the trial, and the presence of clustering were recorded.
Sample size calculation
The methodology sections of the selected articles were studied in full detail, with particular focus placed on sample size calculation. All of the parameters used for the calculation of the sample size were collected. Any assumptions made and justification for the assumptions were also recorded. These parameters included Type I error, Type II error or power, one or two tailed tests, type of test, assumptions made in the control group, and predicted treatment effect.
Adjustment during statistical analysis
The results of the trials were studied and analysed for cluster effect adjustments, especially during statistical analysis of the results. Various models used for the statistical adjustment were also recorded.
Data extraction from the online extra material and trial registration websites
The trial registration websites were accessed and the target sample size and all the parameters used for the sample size calculation for the retrieved articles were recorded. Additionally, the extra materials related to the selected articles which were available online were also accessed and searched for the target sample size calculation and the parameters used for the sample size calculation.
RESULTS
Description of the 130 Included Articles
Table 1 describes the characteristics of the 130 selected articles. In 60 trials (46%), the intervention was delivered by the doctors, including general practitioners, physicians, psychiatrists, and surgeons. In the remaining included studies, the intervention was delivered by nurses in 43 trials (33%), physiotherapists in 16 trials (12%), and acupuncturists in the remaining 11 trials (9%). In half of the selected trials, the intervention was pharmacological, with a nonpharmacological intervention used in 45 (35%) trials. In the remaining 20 trials (15%), mixed method interventions were evaluated.
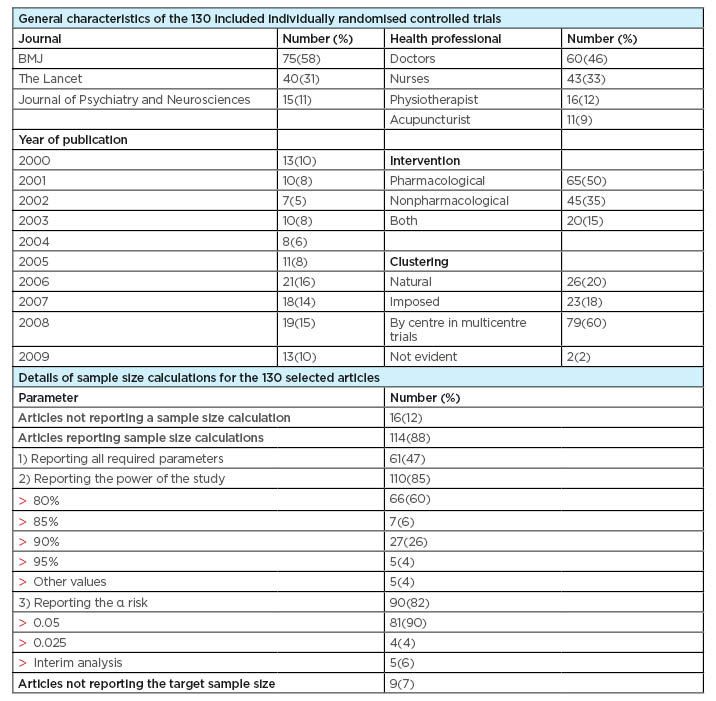
Table 1: Baseline characteristics of the articles and details of sample size calculation.
Types and Prevalence of Clustering
Clustering by centre in multicentre trials was found in 79 trials (60%), followed by natural clustering, which was found in 26 trials (20%). Clustering imposed by the design of the study was noticed in 23 trials (18%), while the form of clustering was not clear in 2 trials (2%).
Allowance for Clustering in the 130 Selected Articles
Table 2 shows the frequency of the trials that corrected for the clustering effect in their study either by making adjustments while calculating the sample sizes or during the statistical analysis. Out of the 130 selected articles, 13 were published during the year 2000. Among these 13 trials, only 2 trials (15%) had adjusted for the clustering effect.
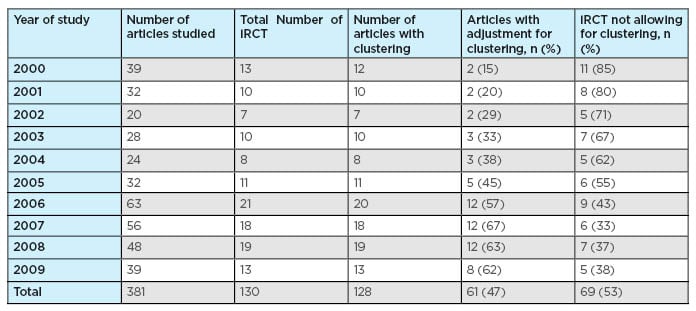
Table 2: Frequency of article allowing and/or ignoring for clustering effect.
iRCT: individually randomised controlled trials.
Likewise, among the 10 trials published during 2001, only 2 trials (20%) had made allowances for the clustering effect. In 2002, 7 articles out of the 130 selected articles were published, and among these 7, only 2 articles (29%) had taken the clustering effect into account. The percentage of trials that took various forms of clustering into account and had made adjustments in their study increased to 45% in 2005 and reached the maximum percentage recorded of 67% during the year 2007. During the year 2008, 12 trials out of 19 (63%) had taken the clustering effect into account. In 2009, of all the trials published up to the search end date, 31st August 2009, 8 trials (62%) showed proper adjustments for various forms of the clustering effect.
Ignoring the Clustering Effects in the 130 Selected Articles
Table 2 summarises the frequency of articles that ignored the clustering effect and made no allowance in their design and analysis. Overall, 69 articles (53%) made no adjustment for the clustering effect in their design and analysis.
Reporting sample size calculations
Table 1 summarises the data about sample size calculation; 16 articles (12%) did not report the sample size calculation, while 9 trials (7%) did not mention the target sample size, neither in the full text report nor on the trial registration database. Even though a sample size calculation was reported by the majority of articles (88%), some of the required parameters for sample size calculation were frequently absent in reports.
In total, 61 articles (47%) included the required parameters for sample size calculations, including the assumptions made for the treatment effect and the control group. Moreover, 110 trials (85%) reported the power of the study. Finally, the α risk was mentioned by 90 trials (82%), which mostly mentioned the two-tailed test.
DISCUSSION
Principal findings
In this study of 130 iRCT published in three medical journals during the 10-year period from 1st January 2000–31st August 2009, the potential for clustering was found to be very common (98%) and only 47% (61/130) of trials studied in this time period have made allowances and adjustments for the clustering effect in their study design and analysis. The time trend analysis showed that the trend of taking clustering into account in iRCT has increased over recent years, from 15% of studies implementing anticlustering measures in 2000 to 67% in 2007, and 63% in 2008. This trend still remains high (62%) for the selected trials published up to the 31st August 2009 in the three selected medical journals.
A plateau in the time trend analysis graph during the years 2008 and 2009 warrants further investigation into the importance of clustering adjustment to further increase the percentage of iRCT that adjust for clustering.
Sample size calculations were reported in 88% (114/130) of articles. Reporting of the sample size calculation has greatly increased in the past decades, from 4% of reports describing a calculation in 1980 to 83% of reports in 2002.21,22 However, some of the required parameters for replication of the sample size calculation are frequently absent in reports.
STRENGTHS OF THE STUDY
Familiarity with the data
Unlike secondary data analysis, in which the data is collected by others and a period of familiarisation is necessary, in this study, the data has been extracted and collected by the researcher, and the data set is self-generated so there is marked familiarity with the structure and contours of the data.
Presence of key variables
Secondary analysis entails the analysis of data collected by others for their own purposes, so one or more key variables may not be present.23 In this study the data has been collected by the researcher, so the data about the key variables (potential clustering effect, sample size, accommodation for clustering) was collected with special attention.
Long study span and multiple medical journals reviewed
In this study, all the papers published in the three medical journals within the 10 years has been reviewed. Two of them are general medical journals with high impact factors: BMJ and The Lancet, while JPN is a specialist medical journal with a low impact factor.
Time trend analysis
It was difficult to have a long enough study span to analyse the change in trend with time on the potential clustering and its accommodation in the trials.
LIMITATIONS OF THE STUDY
It is difficult to assess whether the assumptions made in the iRCT during the sample size calculation to adjust for the clustering effect had been manipulated or not, as only the published data about the sample size has been used for the study. To obtain feasible sample sizes, the assumptions could be manipulated during the study.24 Additionally, the sample size calculations can be manipulated after the completion of the study, as recently shown by Chan et al.25 by comparing protocols to final articles.
The trials with complex designs, such as factorial designs, crossover trials, and trials with >2 parallel arms, were excluded during the screening process to obtain a homogeneous sample of articles. Therefore, the clustering effect and its adjustment in trials with more complex trials have not been assessed. This may limit the generalisability of the results.
Another limitation is that the treatment-by-centre interaction is not considered. However, as the main objective of a trial is often to assess the overall treatment effect, it is recommended to investigate the treatment effect using a model that only contains the centre effect.14,26
CONCLUSION
The issue of clustering by health professionals in iRCT has gained attention in the last few years, and there is need for further research in this field to elicit some more facts about this matter and to provide further guidelines about the anticipation of, and accommodation for, potential clustering. A simulation study will be helpful to demonstrate the clustering affect on the results of an iRCT. Although each and every form of the clustering may not need to be accounted for at the analysis stage,27 this paper highlights the existence of this issue to the readers and reviewers and the need for analysis adjustment in certain cases.